#没有设置高宽参数,将以原图输出)
简介:
一款可以自动提取标题和内容还附带有api推送的采集工具...
有任何问题建议在技术问答下留言
一些不足之处:
不支持php8版本 推荐使用PHP7.4版本
不支持用PhantomJS运行无头浏览器加载网页进行采集
不支持图片下载到本地或OSS
不支持采集的时候支持使用代理
不支持采集的时候使用自定义cookie或ua头
不支持发起post请求,仅支持get
不支持采集api接口

使用说明:
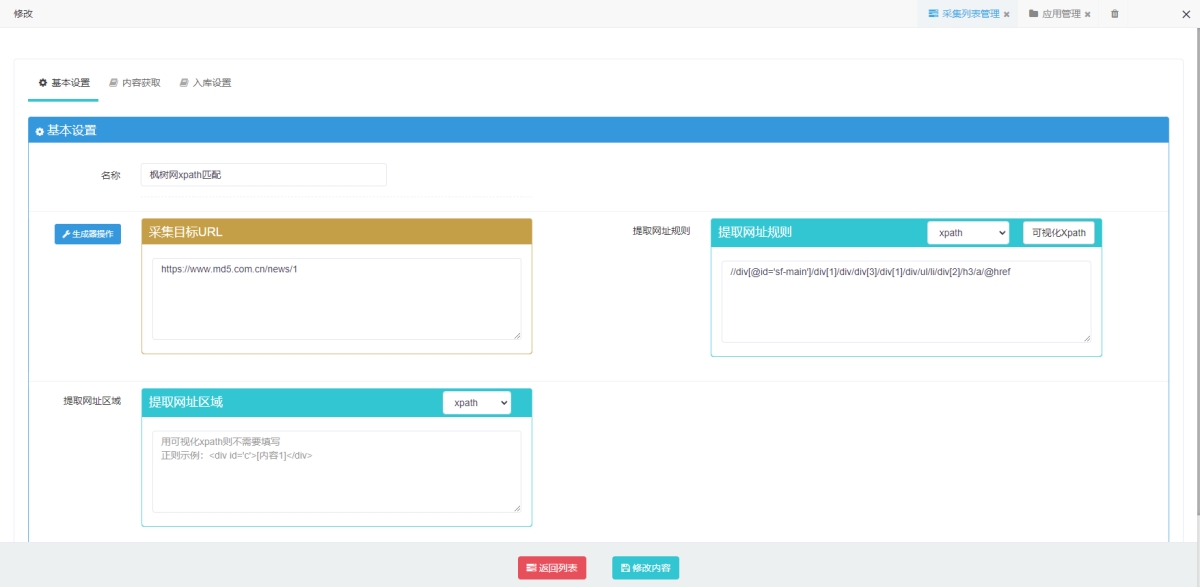
添加采集: 
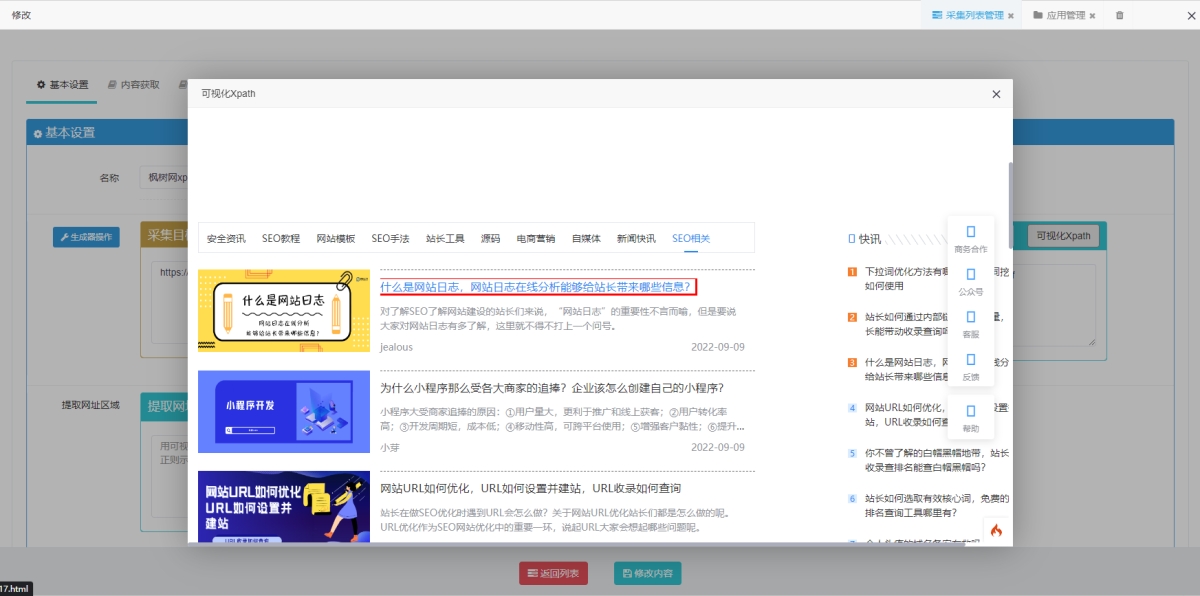
可视化xpath获取文章链接:

可视化xpath获取文章内容:

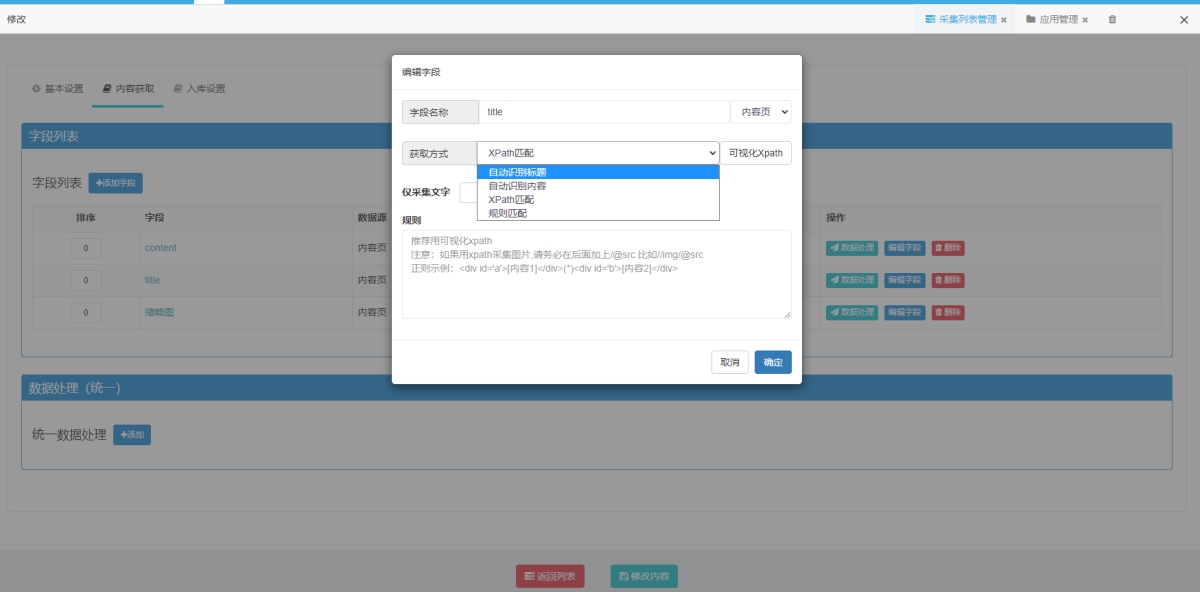
注意
如果是采集图片 在得到的xpath规则后面 要添加/@src
比如用可视化xpath选择图片后 得到xpath规则://*[@id="post"]/img
这时候要手动在xpath规则后面加/@src
也就是//*[@id="post"]/img/@src
入库设置:


先去获取定时任务的链接

如果我想用【定时任务】去采集 名称为 【枫树网自动采集】的采集任务
可以看到 这个采集任务的id为1
所以采集链接为:http://caiji.md5.com.cn/index.php?s=Puyicaiji&c=collect&m=run&mode=list&token=4ec546f2d22a6cfa&id=1
得到链接后 就可以设置定时任务发起curl请求去定时采集了
但有两点要注意:
1.建议把PHP和NGINX的超时时间设置久一点 比如300秒,如果PHP或nginx超时时间过短 会导致采集失败
2.发起curl请求的时候 curl也有超时时间 建议好设置为长一点 比如300秒 (不过还是受限于PHP和nginx的超时时间)
设置curl超时时间的命令为:
curl --max-time 300s http://caiji.md5.com.cn/index.php?s=Puyicaiji&c=collect&m=run&mode=list&token=4ec546f2d22a6cfa&id=1
以宝塔为例
每1小时执行一次采集任务
而且一次执行三个任务
采集任务id分别为1,2,3

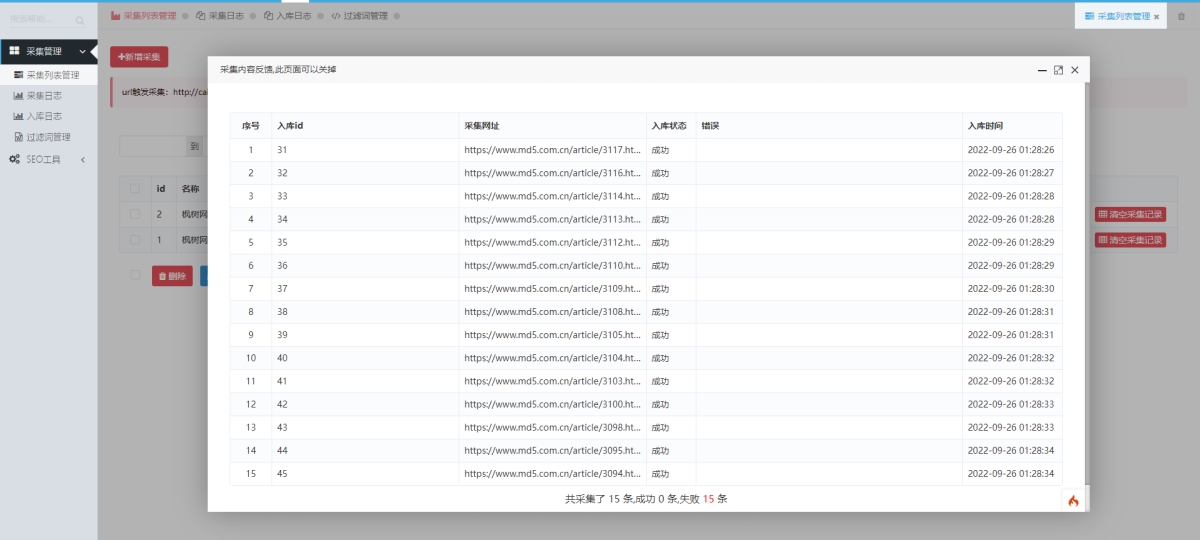
不管是定时任务还是手动触发采集
如果文章链接已经被采集了
是不会重复采集的
其他功能:
数据处理:

全局过滤词:

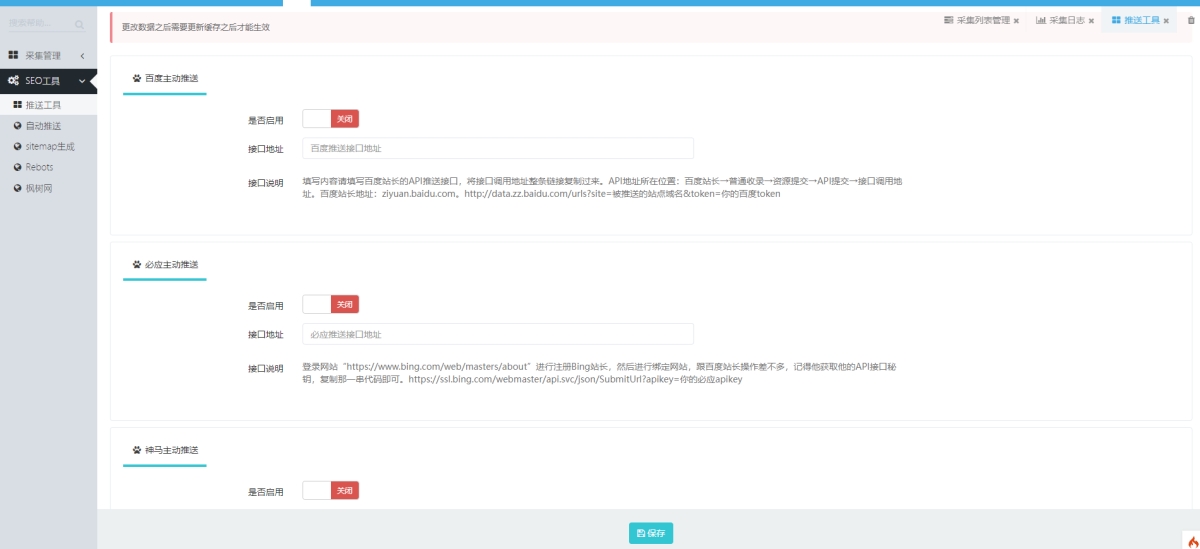
百度、必应、神马的api推送:

robots生成:


#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)
#没有设置高宽参数,将以原图输出)



